
私はAI関連だけでなく、デジタルマーケティング的なことにも取り組んでいます。
この流れで、ときどき特定のキーワードでGoogleで上位表示されてる記事のHタグ構成をチェックすることがあります。
でも、1つ1つURLを取得して、1つ1つ記事構成を調べるのはけっこう面倒。
ということで、n8nとApify(エイピファイ)を組み合わせ、記事構成抽出を自動化するツールを作りました。
自動化した流れは以下。
- n8nで検索キーワード&取得するサイト数を指定
- ① の条件で上位表示されるサイトのURLを取得
- Apifyでtitle・description・Hタグ構成をスクレイピング
- Googleスプレッドシートに書き込む
n8nのワークフローは以下。

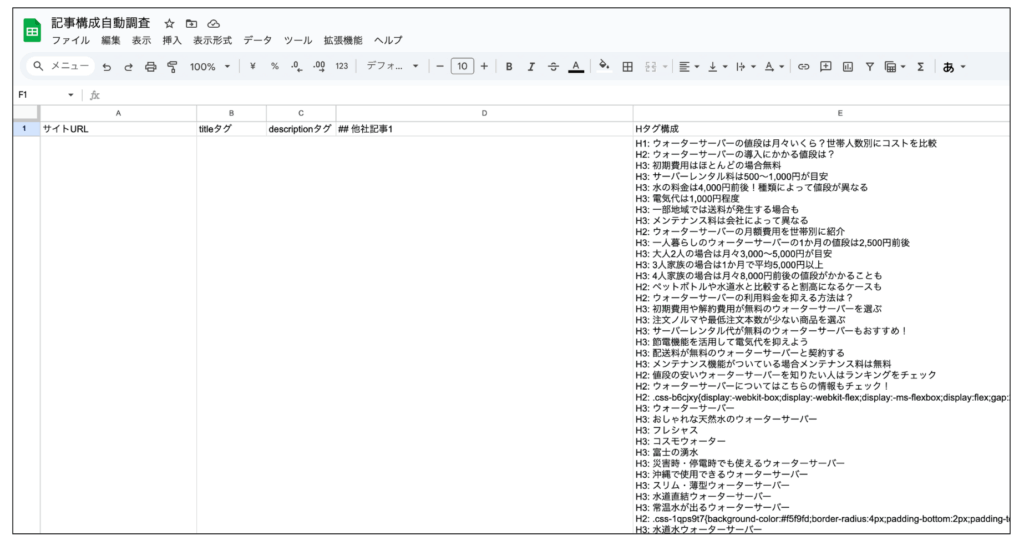
このワークフローを実行すると、以下のように、検索エンジンで上位表示されてる記事の記事構成がスプレッドシートに書き込まれます。
※「ウォーターサーバー 料金」というキーワードで調査
※サイトURL・title・descriptionも取得されます
これから、このワークフローを作る方法を紹介します。
初心者向けのツールではないこともあり、詳細にわたっては解説しませんので、ご了承ください。
もし不明点等があれば、この記事の最下部にある私のプロフィールからXアカウントにDM等でお気軽にお問い合わせください。
それでは、解説を進めます。
STEP① ApifyやGoogle関連のAPIキー等を用意
このワークフローを完成させるにあたっては、以下が必要です。
- SerpAPI → URLを取得するのに使う
- Apify API key → 記事内のHタグ等を取得するのに使う
SerpAPIは検索エンジンで上位表示されてる記事のURLを取得するのに使います。
以下のURLから簡単に取得できます(無料)。
https://serpapi.com/
Apify API keyはスクレイピングするのに使います。
以下のApify公式サイトから無料会員登録し、取得できます。
・Apify公式サイト
https://apify.com/
ApifyのAPIは無料会員でも使えます。
ただ、無料会員のままだと毎月5ドル分しか使えません。
とはいえ、特定のキーワードを指定してWEBサイトのスクレイピングするくらいでは5ドル分使い切ることはまずありません。
私も今回のツールを作るにあたり何回もスクレイピングしましたが、消費は0.1ドル未満です。
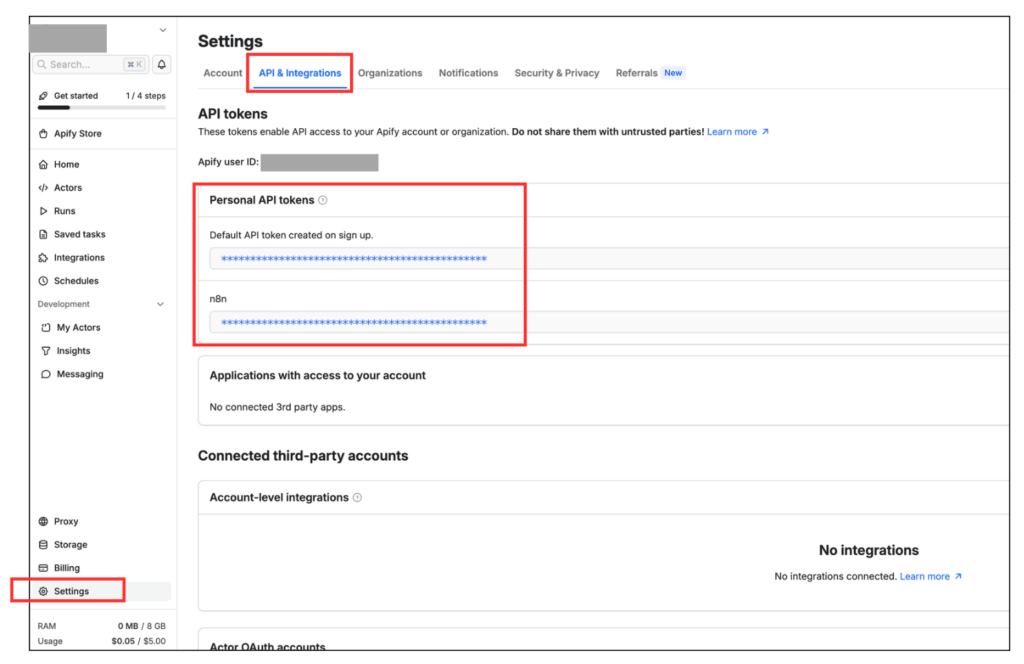
ApifyのAPIキーは
- サイドバー下にある「Settings」をクリック
- サイト上部にある「API & Integrations」をクリック
- 「Personal API tokens」の箇所
という流れで取得できます。
ちょっとわかりにくいので、下の画像を参考にしながら取得してください。
取得した記事構成を書き込むGoogleスプレッドシートも準備しておきましょう。
用意といっても、新規でスプレッドシートを作成し、1行目に以下のテキストを書き込むだけです(テキストはお好みで変えてOK)。
- A列1行:サイトURL
- B列1行:titleタグ
- C列1行:descriptionタグ
- D列1行:## 他社記事1
- E列1行:Hタグ構成
あと、書き込み先のスプレッドシートのIDも控えておいてください。
IDはスプレッドシートに表示されるURLを見れば確認できます。
以下のサンプルURLでは、「〇〇」の部分がIDに該当します。
https://docs.google.com/spreadsheets/d/〇〇〇〇〇〇〇〇〇〇〇〇〇〇/edit?gid=0#gid=0
以上で準備は完了です。
STEP② 検索結果上位記事のURLを取得
ここからの作業はn8nで行います。
最初に、指定したキーワードで検索結果の上位に表示される記事のURLを取得します。
新しいワークフローを作ったら、最初にManual Triggerノードを追加します。
これはワークフローを手動で開始するためのスイッチのようなものです
追加したら、次はEdit Fieldsノードを追加します。
Edit Fieldsノードの「Fields to Set」の部分を以下の画像のように設定してください。
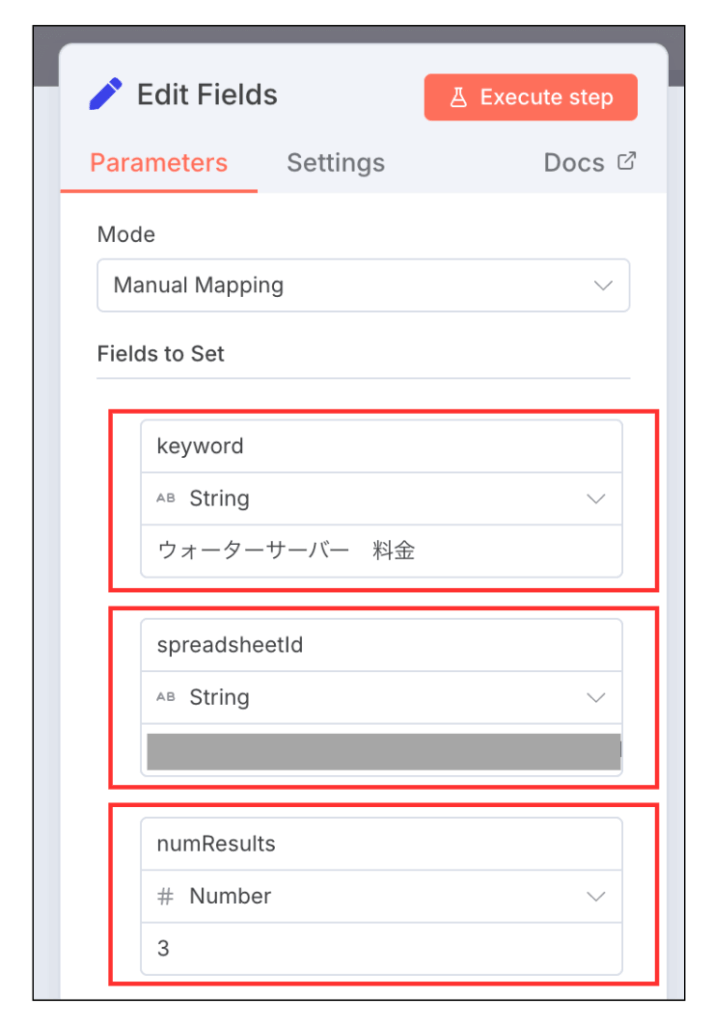
設定するのは以下の3つですね。
- keyword→String→ウォーターサーバー 料金
- spreadsheetId→String→データを書き込むスプレッドシートのID
- numResults→Number→3
補足すると、「keyword」に記事構成を調査したい検索キーワードを入れます。
ここのキーワードを変えれば、異なるキーワードを調査できます。
「numResults」は取得する記事数を入れる箇所です。
網羅的に調査したいときは10くらいにすると良いと思います。
画像内の設定だと
「ウォーターサーバー 料金」というキーワードで上位表示されてる記事3つを取得する
という意味になります。
次はCodeノードを加えます。
ノード内に「JavaScript」という項目があるので、以下をコピペしてください。
// SerpAPIの結果からorganic_resultsを取得
const organicResults = items[0].json.organic_results || [];
// 各結果からURL、title、descriptionを抽出
const processedResults = organicResults.map((result, index) => {
return {
rank: index + 1,
url: result.link || '',
title: result.title || '',
description: result.snippet || ''
};
});
// Cheerio Scraper用の完全なInput JSONを作成
const apifyInput = {
startUrls: processedResults.map(result => ({
url: result.url
})),
pageFunction: "async function pageFunction(context) { const { $ } = context; const headings = []; $('h1, h2, h3, h4, h5, h6').each((i, el) => { headings.push({ tag: $(el).prop('tagName').toLowerCase(), text: $(el).text().trim() }); }); const description = $('meta[name=\"description\"]').attr('content') || ''; return { headings: headings, description: description }; }"
};
return [{
apifyInput: apifyInput,
processedResults: processedResults
}];
ここまでで、以下のワークフローが作れていると思います。
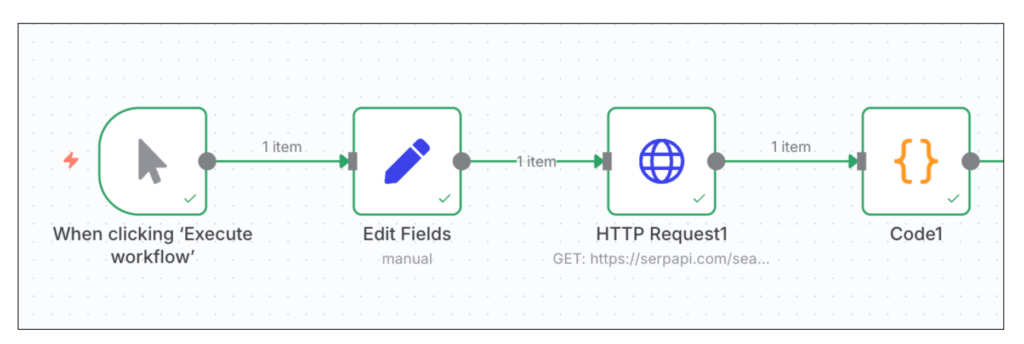
STEP③ Apifyノードでスクレイピング設定
ここからはApifyノードを使います。
ただし、Apifyはデフォルトではn8nにインストールされていません。
n8nから「Apify」とノード検索し、
「Install node」
ボタンをクリックしインストールしてください。
インストールすると、以下のようにApifyノードが選択できるようになります。
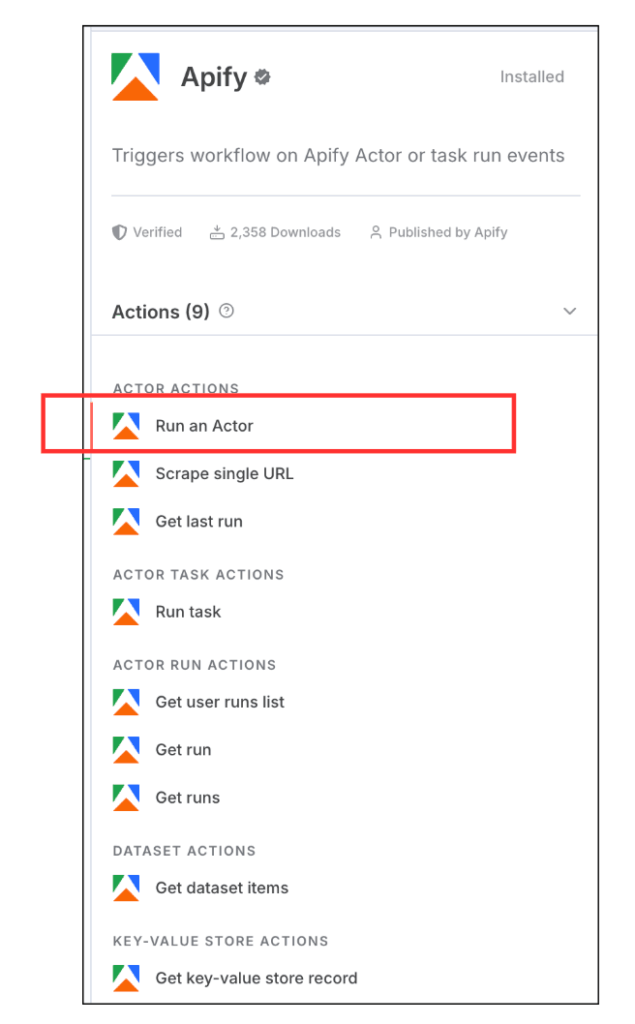
この中から
「Run an Actor」
を選択し、ワークフローに追加してください。
※Apifyではスクレイピングツールのことを「Actor」と呼びます。
追加したら「Apify API key connection」の部分で「Create new credential」をクリックし、次の画面で取得しておいたAPIキーを入れます。
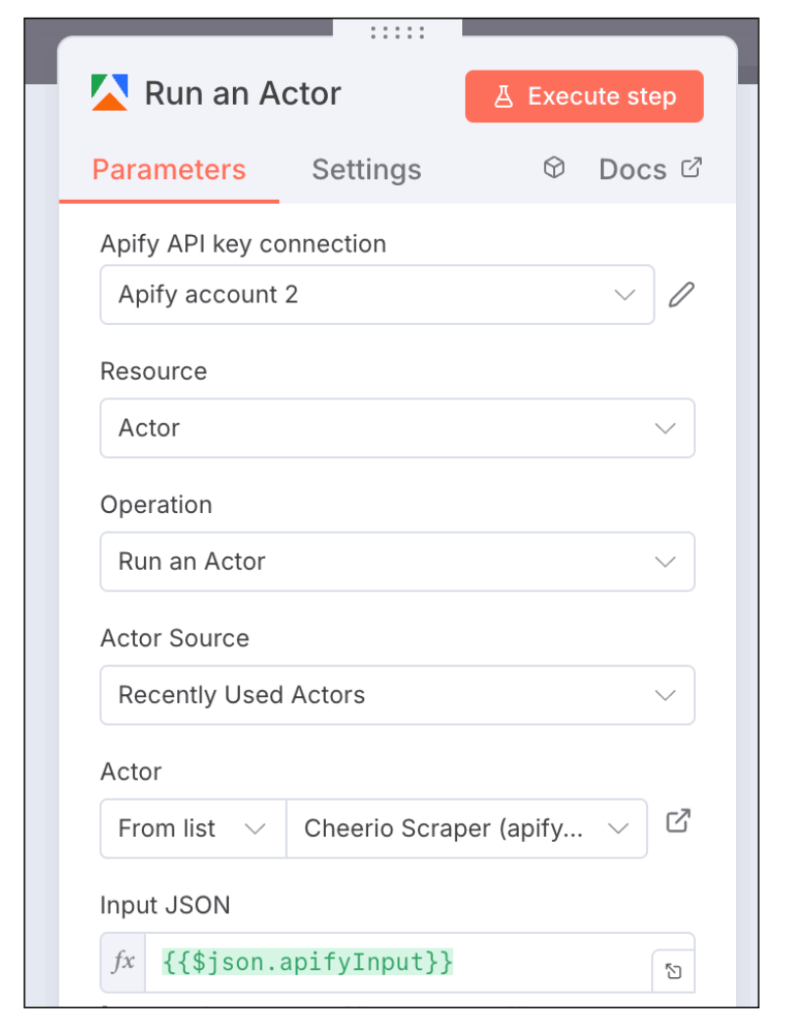
認証が完了したら、以下のように設定してください。
- Resource:Actor
- Operation:Run an Actor
- Actor Source:Recently Used Actors
- Actor:Cheerio Scraper (apify/cheerio-scraper)
- Input JSON:{{$json.apifyInput}}
これで、Apifyがスクレイピングできるようになります。
ApifyのActorが取得したデータは「Dataset」と呼ばれる格納庫のようなものに保存されます。
よって、次のノードでDatasetに格納された情報を引き出します。
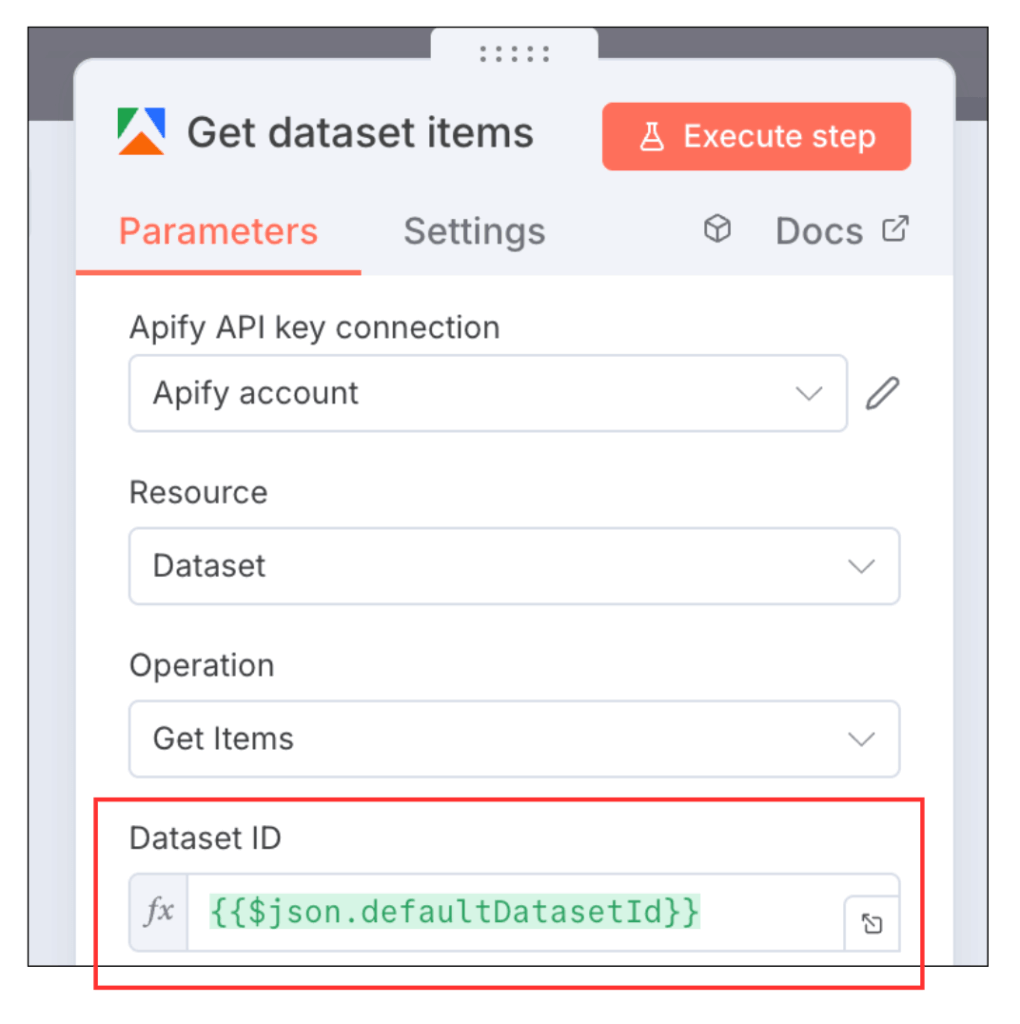
ここでは同じくApifyノードの中の「Get dataset items」を使います。
Get dataset itemsを追加してください。
追加したら、Dataset IDという項目に
{{$json.defaultDatasetId}}
を入れるだけで設定完了です。
このステップでは以下の2つのApify関連ワークフローをn8nに追加しました。
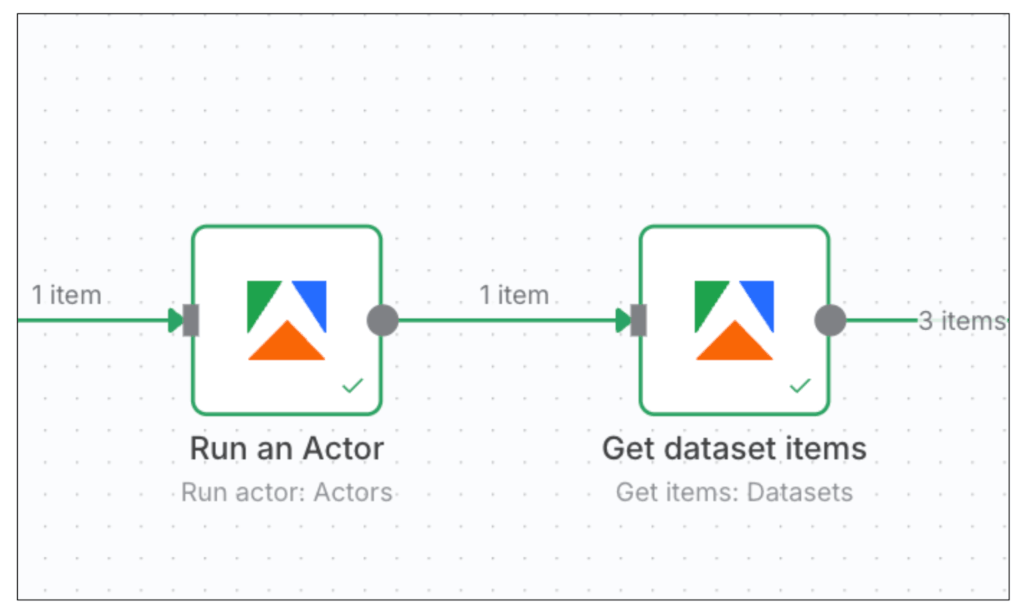
これにより、検索結果で上位表示されてるサイトの記事構成が取得できるようになりました。
最後のステップでは、収集した情報をGoogleスプレッドシートに書き込む処理を行います。
STEP④ Googleスプレッドシートに書き込む
Googleスプレッドシートの設定に入る前に、Apifyで収集したデータを人でも見やすいように加工します。
使うノードはCodeノードです。
Codeノードを追加し、以下のJavaScriptをコピペしてください。
// Apify Datasetからの結果を整形
const scrapedData = $input.all();
const sheetsData = scrapedData.map((item, index) => {
const site = item.json;
// Hタグ構成を見やすい形式に変換
const htagStructure = site.headings
.map(h => `${h.tag.toUpperCase()}: ${h.text}`)
.join('\n');
return {
rank: index + 1,
url: site['#debug'].url,
title: site.headings.find(h => h.tag === 'h1')?.text || 'No H1 found',
description: site.description,
htagStructure: htagStructure
};
});
return sheetsData;
最後に追加するのはGoogle SheetsのAppend row in sheetノードを追加します。
※初回だけGoogleアカウントとの連携認証が必要
DocumentとSheetは、データの書き込み先となるスプレッドシートを指定してください。
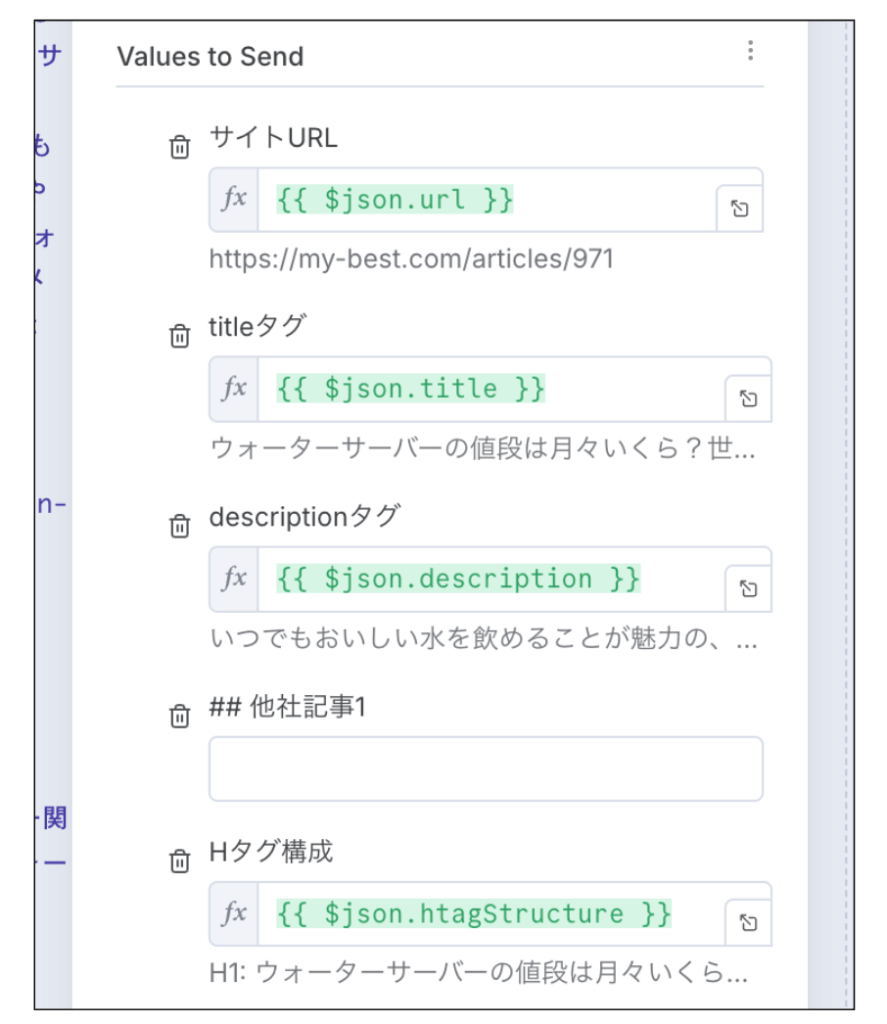
残りの設定項目は「Values to Send」だけです。
以下のように設定してください。
- サイトURL:{{ $json.url }}
- titleタグ:{{ $json.title }}
- descriptionタグ:{{ $json.description }}
- ## 他社記事1:空欄でOK
- Hタグ構成:{{ $json.htagStructure }}
設定したら実行してみてください。
情報が取得され、スプレッドシートに書き込まれていれば成功です。
ワークフローはこれで完成です!
生成AIノードを追加し、記事構成を自分の記事と比較することも可能
今回紹介したワークフローに生成AIのノードを追加すれば
- 検索結果で上位表示されてる記事
- 自分が書いた記事
などを比較することも可能です。
そうすれば、AIが自動で分析し、記事構成を提案してくれるでしょう。
ただし、SEO的に優れた記事構成を作るポイントは、ただ上位記事のHタグを真似ることではありません。
大事なのは上位記事の記事構成を見て、読者が求めるコンテンツを発見することです。
読者は悩みや問題を解決するために検索し、記事を読みます。
つまり、上位記事の構成を調査するのは
「読者がどんなことに悩んでいるか」
これを理解するためです。
ただ上位記事のHタグを真似ても、その記事を超えることは難しいです(例外はあります)。
読者の悩みを正しく理解し、上位記事よりも早く、深く読者の悩みを解決する記事を作りましょう!
今回紹介したツールがnoteやブログなど、みなさんの記事作りのお役に立てたら幸いです。